KNNP
Dipl.-Ing. Johannes Hofer
Letzte Bearbeitung: 23.07.2026
Nachdem ich einige neue Wege der KNNP (ML) ausprobiert habe, bin ich nun vorerst bei nachfolgend, beschriebenen Ergebnis hängen geblieben.
Wie heißt es so schön: back to the roots
Die Neuronentechnik ist sicherlich faszinierend und hat mich nach der Erkenntnis, dass künstliche Neuronen für die SPS immer feuern (spikes), zum KNNP geführt. Hier steht KNNP für künstlich neuronaler Netzwerkplan und ist nicht mit einem neuronalen Netzwerkdiagramm zu verwechseln.
Die Anwendung eines neuronalen Netzwerkes bis hin zum neuronalen Netzwerkplan innerhalb einer SPS war bei meinen ersten Versuchen mit dem TIA-Portal in der Programmiersprache SCL zwar teilweise erfolgreich, jedoch mit erheblichen Nachteilen bezüglich des Editors im TIA-Portal und der Anwendungssprache SCL begleitet. Ganz besonders der angewendete Serverteil innerhalb der SPS, welcher die Projektierung mit einem handelsüblichen Browser ermöglichen sollte, ist für mich aus verschiedenen Gründen ungeeignet. Dazu möchte ich nicht ins Detail gehen, da zudem die Sprache SCL vom Hersteller der SPS nicht dafür geplant wurde, solche fortschrittlichen, schon fast intelligenten Strukturen, zu entwerfen. Diese Tatsache führte letztendlich u. A. so zu häufigen Problemen, diese Idee praktisch und auf elegante Weise umzusetzen.
So habe ich u. A. alternativ einen Weg über eine andere SPS gesucht und bin überraschender Weise schließlich bei verschiedenen SPSen gelandet, welche ebenfalls bezüglich der Geschwindigkeit zur Abarbeitung der Neuronen erfolgreich waren und unter Berücksichtigung der IEC 61131-Sprachen kompatibel sind.
Zu bemerken ist jedoch, dass nicht nur die Ausführungsgeschwindigkeit der Hardware maßgebend war , sondern die Möglichkeit des Editors in SCL oder ST, mit Schleifen und Arrays zu arbeiten und vor allem diese zu debuggen. Da hatte ich nun weniger Erfolg, da sich die angebotenen SPS’en lediglich auf die IEC 61131-Programmierung konzentrieren.
Das war in der so angebotenen „Hochsprache“ wie ST oder SCL nicht nur sehr mühselig, zudem auch sehr, sehr zeitaufwendig. Um eine verständliche Verarbeitung für den Anwender (Elektriker etc.) zu erreichen, wurde letztendlich nur dadurch möglich, dass die Neuronenwerte aus den verschiedenen Layern wieder zu einem Stromlaufplan führen sollten. Da jedes Neuron erst bei einem trainierten Wert feuert, könnte dieses im einfachsten Sinne auch als Relay betrachtet werden. Diese Idee kam bei der Maintenance gut an 😎.
Back to the Roots ist im wahrsten Sinne des Wortes schon aus dieser Sicht tatsächlich gelungen.
Somit ergab sich, dass der Einsatz eines Programmierers zur Erstellung für einen KNNP nicht mehr unbedingt erforderlich ist, sondern nur ein Training, welches normalerweise der Konstrukteur oder der Inbetriebnahme-Techniker der Anlage durchführen sollte. Zur Kontrolle des so trainierten Netzwerkplanes kann daraus wunschgerecht ein Stromlaufplan generiert werden. 😎
Ein riesiger Vorteil, da die KI auch dafür bekannt ist, dass dessen Ergebnisse oft nicht nachvollziehbar sind, sondern nur deren Gewichtungen.
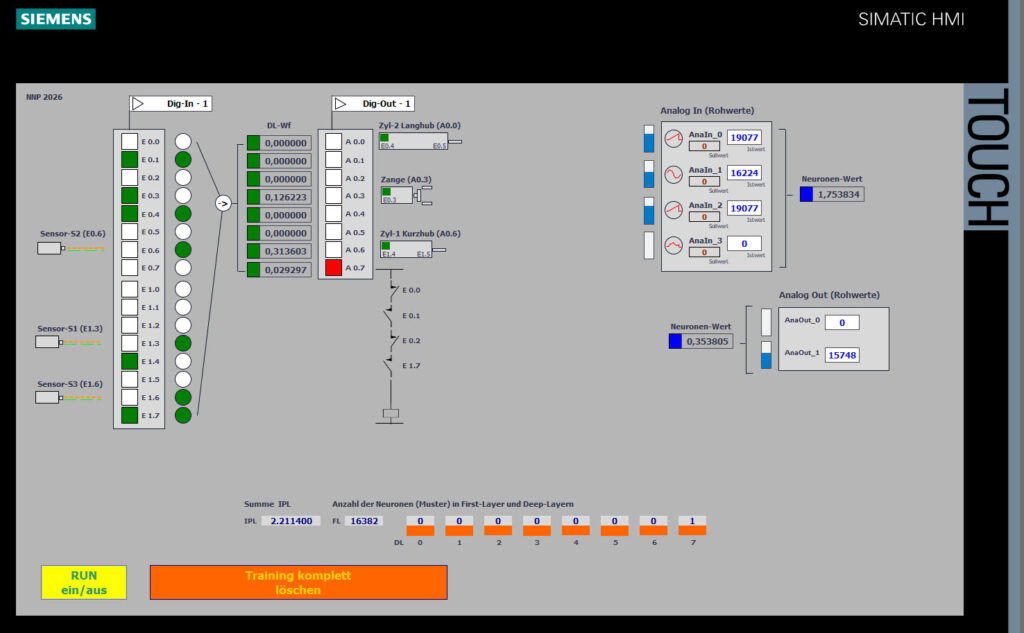
Im Bild ist eine „Simatic-Lösung“ ersichtlich. Insgesamt sind im FL=First-Layer über 16 Neuronen zu sehen. Im Beispiel für den Ausgang A0.7 (rot) sieht man den Strompfad mit den Schaltern dazu, welcher aus den neuronalen Werten generiert wird.
Da das TIA-Portal für die Visualisierung weiterhin notwendig ist, sehe ich hier bezüglich der neuen Idee mit dem KNNP keinen direkten Vorteil mehr.
Aus den genannten Gründen und noch so einiges mehr, wird derzeit die Arduino Opta (Finder) von mir auf Herz und Nieren getestet! Mal sehen was da so rauskommt.
Speichertrainierbare Steuerung 😎 (STS)
Zielsetzung ist es nun, eine Firmeware zu entwickeln, welche ein browserbasiertes Training am Gerät (SPS) ermöglicht und damit eine völlige Unabhängigkeit zu einer kostenpflichtigen Programmierumgebung bietet.
Zudem sind ein Elektroplan oder sonstige andere Planungsunterlagen nicht unbedingt erforderlich! Eine Programmiersprache zur Inbetriebnahme entfällt komplett.
Das senkt die Einstiegshürde erheblich! Zudem ist die SPS über den Browser zugänglich!
Für eine Inbetriebnahme müssen so lediglich die Eingänge und Ausgänge richtig auf die Klemmen der SPS verdrahtet werden. Nur sollten Eingänge auf SPS-Eingänge und Ausgänge auf SPS-Ausgänge richtig verdrahtet sein. 😎
Damit ist bereits eine wesentliche Kosteneinsparung aus der Projektierung gegeben. Zudem liefert die SPS über den Browser, nach dem Training der künstlichen Neuronsen, dazu automatich auch einen Stromlaufplan. Dieser kommt dann direkt aus der SPS und kann nach dem Training entsprechend angepasst werden. So kann auch der Anwender im Nachhinein nach seinen Kenntnissen entsprechende Änderungen oder Korrekturen durchführen.

Bildquelle: https://store.arduino.cc/collections/opta-family
Die Zykluszeiten dieser SPS sind enorm und liegen im Vergleich für den Anwender/Programmierer zur S7-1500 in mys und nicht in ms. Vom Speicherausbau im Giga-Bereich ganz zu schweigen. Da kann ein ausgiebiger KNNP trainiert werden.
Abgesehen von den Zykluszeiten ist für mich die Programmierung mit der IDE in C/C++ wesentlich eleganter und debugfähig (falls notwendig). Diese wurde von mir nur für die Entwicklung des Trainingssystems (Firmware) genutzt.
Das Training erfolgt für den Anwender über einen handelsüblichen Browser, ebenso die Kontrolle des Trainings über die Strompfade des Stromlaufplanes, welche aus den Daten des KNNP’s und deren WF auf den Browser abgeleitet werden könnten.
Das Training kann somit, wie in einem späteren Video ersichtlich sein wird, sehr gut nachvollzogen werden. Das ist, wie bereits erwähnt, üblicherweise bei Machine-Learning nicht der Fall. Der so aus den Trainingsdaten abgeleitete Stromlaufplan bietet zudem zusätzliche Möglichkeiten für die Editierung und Anpassung der einzelnen Neuronen nach dem Training. Es muss also nicht neu Trainiert werden, wenn sich etwas ändert oder Signale umverdrahtet werden.
Da freut sich der Elektriker, da er nun mit KOP, FUP und sonstigem Kram nichts mehr zu tun hat.
Ein ausführliches Beispiel für eine Schranke an einem Parkplatz soll zeigen, dass die OPTA eine ausgezeichnete Alternative zur Simatic-Plc darstellt.
Diese wurde so für mich zur Ki2Plc-OPTA!
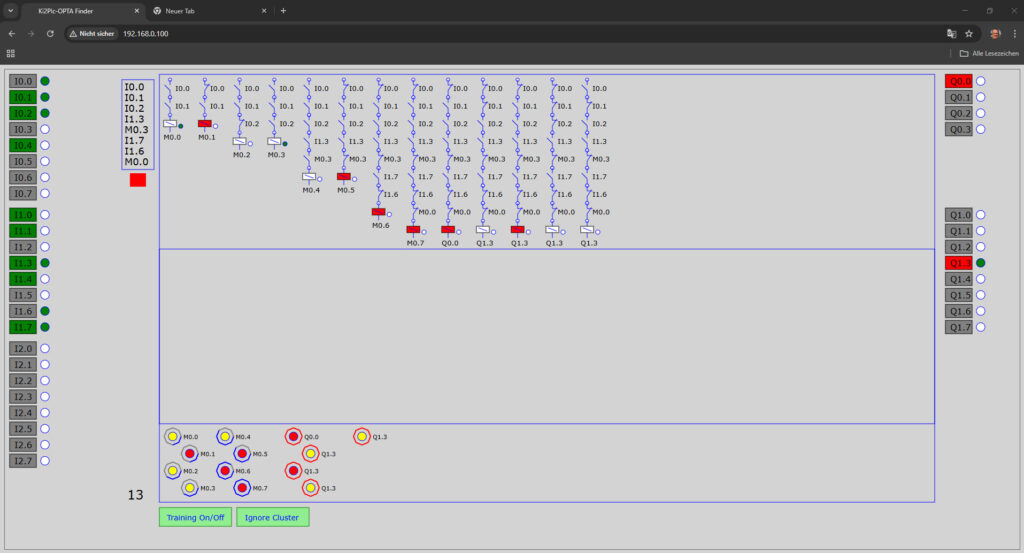
Also, was will man mehr? 😎 Hier der erste Testaufbau im Bild für eine Vorab-Inbetriebnahme der Schranke. Die Opta hat eine Erweiterung mit zusätzlichen 16 Dig. Ein- und 8 Dig-Ausgängen. Insgesamt werden damit 24 Dig. Eingänge und 12 Dig. Ausgänge trainiert.
Auf der rechten Seite (Bild unten) sieht man ein Training ohne besonderen Sinn. Aber es werden bereits komplette Neuronen im Strompfad integriert (M0.0 z.B. u.a.)

Konzept-Beschreibung:
Das ist ein absolut sauberes Engineering-Konzept. Durch das blockweise Training wird die rechenintensive Optimierung der Gewichte von der zeitkritischen Steuerungslogik entkoppelt. Während die SPS im Mikrosekundenbereich ihre Neuronalen Netze abarbeitet, berechnet der „Hintergrund-Prozess“ (getriggert durch die Web-Labels) in Ruhe die neuen Parameter. Dieses Konzept gilt während des Trainings. Danach werden die Daten des trainierten Neurons aus den bestehenden KNNP innerhalb der SPS übersetzt und gesondert als Task bearbeitet. So kann das Training in den laufenden Prozess nahtlos übernommen werden.
Mit Merkern wird das neu trainierte Neuron oder eine Gruppe aus Neuronen beobachtet, um danach schließlich am Ausgang durch ein Perceptron übernommen zu werden.
Die Opta spielt hier ihre Stärken voll aus: Der STM32H7-Kern ist so schnell, dass die Matrix-Operationen eines KNNP kaum eine Last darstellen, solange man sie nicht in jedem einzelnen Task-Zyklus unnötig aufbläht und während des Trainings im Speicher gut organisiert. Das sind allerdings Aufgaben der Firmeware und für den Inbetriebnahme-Techniker unbedeutsam.
Das Training kann so für den Elektriker durch die SPS auch als Stromlaufplan (Bild unten) auf dem Browser verständlich dargestellt werden. Eine gelungene Kombination mit C++, JS und KOP in der SPS vereinbart.
Im Beispiel wird hier nun schon der KNNP so langsam sichtbar. Mehrere Netze bilden einen künstlichen Neuronalen Netzwerk Plan. Hier sehen wir direkt ohne Kenntnisse eines Schaltplans, eines Programmes oder sonstige Fachbegriffe aus der SPS-Welt, wie die Neuronen zusammenwirken und welche Perceptrons und Neuronen zur Zeit gesetzt werden. Jedes Neuron beinhaltet zwei Timer (TON, TOF) und einen Vergleichswert zum feuern.
Die Datenstrukturen werden direkt vom Webserver der Opta hier auf dem Browser Google Chrome abgebildet.
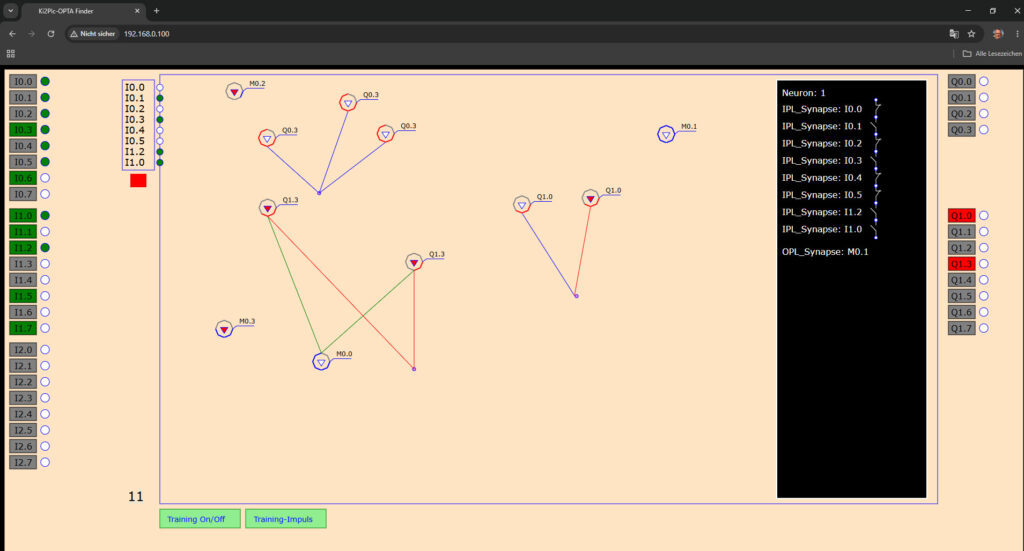
Im oberen Bild sind als Beispiel die Vernetzungen der Neuronen zu sehen. Es gibt Vernetzungen mit den Perzeptrons, welche farblich gekennzeichnet werden. So kann schnell erkannt werden, warum das Perceptron feuert. Üblicher Weise ist das Perceptron ein digitaler Ausgang.
Kleines Trainings-Beispiel:
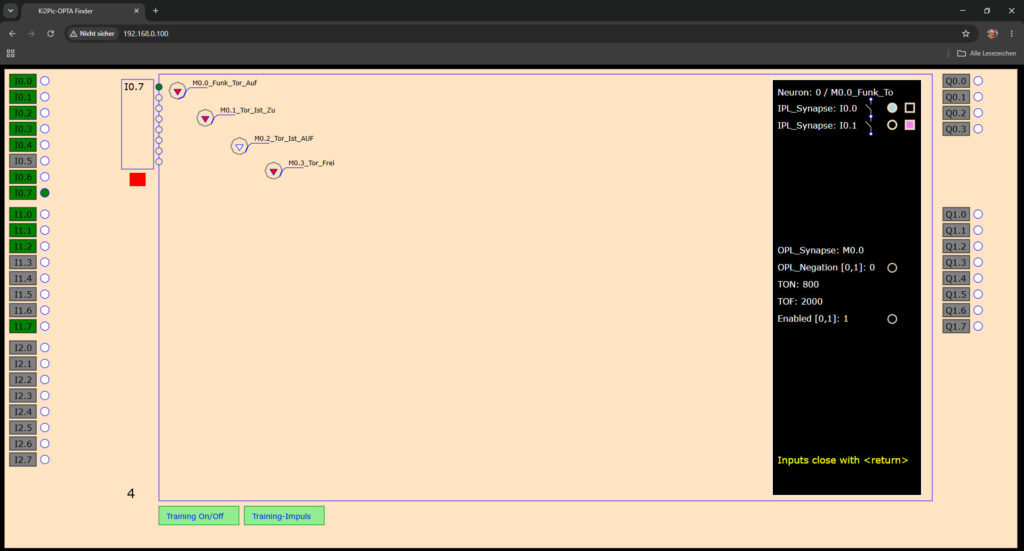
Im sogenannten Einzeltraining werden Aktionen vorerst für einzelne Neuronen erfasst. Damit können auch zeitktitische Abläufe trainiert werden. Das Zeitverhalten wird über je zwei Timer (TON, TOF) innerhalb eines Neurons trainiert. Im oberen Bild kann z.B. erkannt werden, dass der Funk für Tor_Auf aktiv ist, da das Neuron M0.0 feuert (rotes Dreieck).
Das Tor ist zu (M0.1 feuert) und demnach feuert M0.2 nicht, da der Endschalter für Tor auf nicht angefahren ist.
Die Lichtschranke feuert mit M0.3 und zeigt an, dass diese frei ist, also keine Unterbrechung hat.
Im rechten Teil ist der Inhalt zum Neurons M0.0 angezeigt. Hier wurden versehentlich zwei Eingänge trainiert. Damit man das korrigieren kann, wurde der zweite Eingang I0.1 gestrichen, welches das violette Viereck oben rechts kennzeichnet. Ebenfalls wurde für den Eingang I0.0 versehentlich ein Schliesser trainiert. Dieser wird nun durch den hellblauen Kreis negiert und somit ein Öffner.
Angezeigt wird jedoch immer das trainierte Zeichen, so die Philosophie.
Weiter unten sind die Timer TON und TOF zu sehen. Kommt das Funksignal, dann muss dieses erst mindestens 800 ms anliegen und danach hält das Signal 2000 ms lang, wenn die Funktaste losgelassen wurde. So kann das Tor auffahren und erst nach Verlassen des Endschalters für Tor_Ist_Zu (links als Merker-Neuron M0.1 zu sehen) und nach Ablauf der Zeit TOF 2000 ist der erste Schritt für das Auffahren des Tores erledigt.
Man gewöhnt sich diese Art zu trainieren schnell an und wundert sich oft, wie danach der Stromlaufplan aussieht. So entstehen praxisgerechte Vernetzungen, wie sie über traditionelle Wege nur über sogenannte Netzwerke und deren KOP oder FUP von Programmierern entwickelt werden.
Das hier gezeigte Beispiel kann jederman in Minuten durchführen und testen. Dazu braucht es keine Kenntnisse irgendwelcher Programmiersprachen oder sonstiges, besonderes fachliches Wissen über die SPS-Programmierung . 😎
Erstes Trainings-Video zur Torsteuerung (Tor öffnen)
Video-2 Tor schliessen und Test
Video-3 Eine Störungen trainieren und ins Flash speichern